
Tech companies run on acronyms. If you’ve ever sat in on one of our stand-ups, you’ve probably heard at least five before your coffee cooled. Figuring out what they mean, and more importantly, why they matter, is a key aspect of innovation in this space. In our recent knowledge share session, I took the team through how OCR works and our innovative approach to leveraging this technology.
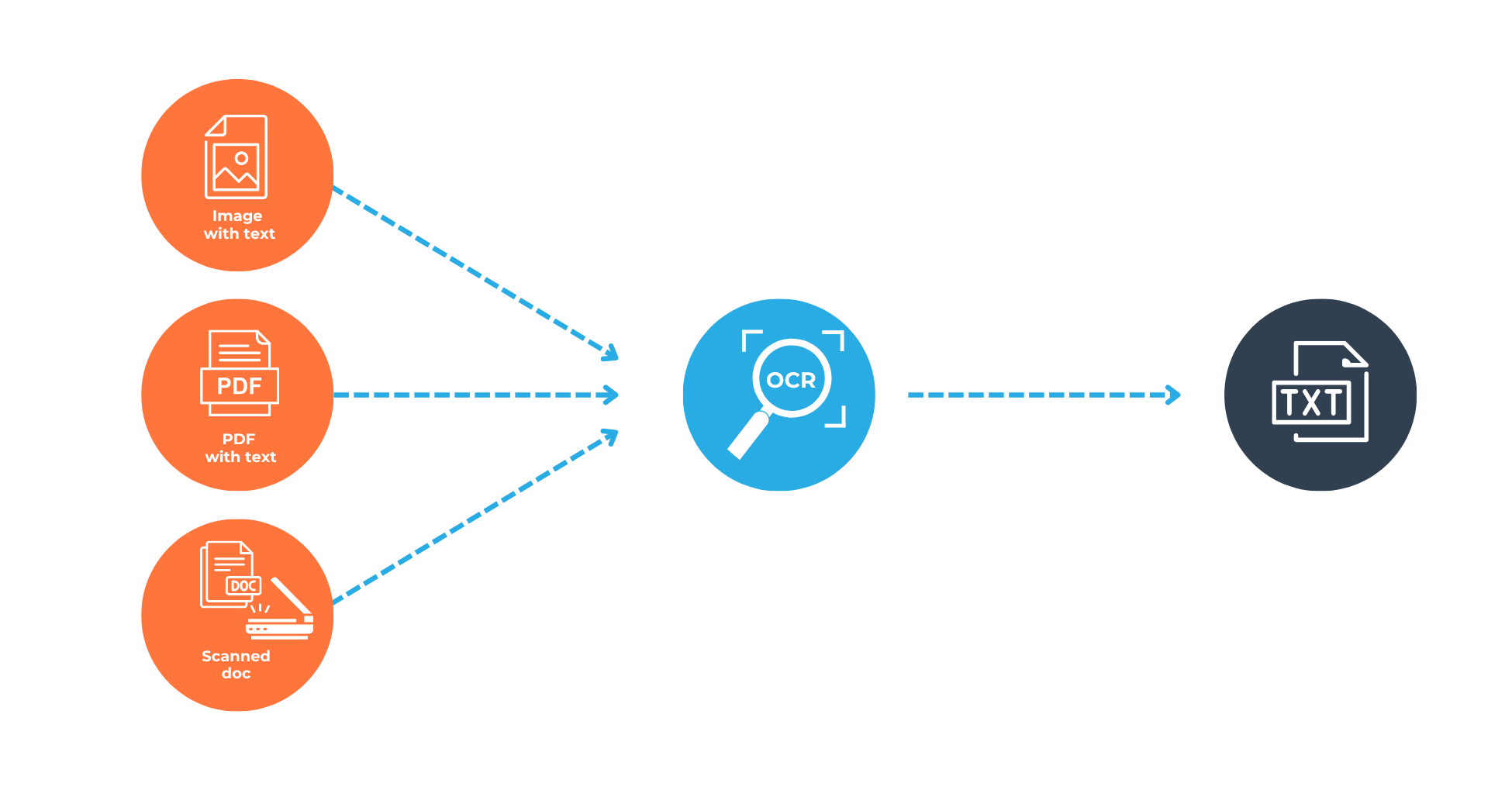
OCR is one of those acronyms we use daily, but what does it actually mean? Optical Character Recognition (OCR) is the technology that converts scanned documents, PDFs, or even photos of documents into data we can edit, search, and analyse. In simpler terms, it’s how you turn a pixel of a bank statement into data you can work with. It’s what makes document digitisation possible, letting businesses shift from filing cabinets to data pipelines.
But it’s not just about having digital copies of paperwork. It’s about making those documents actionable. Whether you’re trying to reconcile transactions, run credit checks, or onboard a client, having structured, searchable data is critical.
Without OCR, every piece of data trapped in a PDF is a manual task waiting to happen, costing businesses time and resources. At Finch, we’re dedicated to removing such friction with innovative solutions.
– Farhaad sallie, intermediate software engineer
How does OCR work in practice?
At Finch, we’ve been using cloud-based document intelligence services to help extract real data from real documents at scale. An Automated Data Extraction Solution is a machine learning service that goes beyond simply extracting printed text. It can handle handwriting and, importantly, it can detect key-value pairs and table structures, which is crucial for documents like bank statements.
Let’s give you an example: when we process scanned bank statements, we start by identifying unique markers, things like logos, header structures, or certain keywords, to determine which bank’s statement we’re dealing with. Once identified, we assign a template to the statement. These templates act like a map, instructing the document extraction engine on where to look for specific information, such as transaction dates, amounts, account numbers, and balances.
The challenge of templates
So, why isn’t this the perfect solution?
Here’s the reality: Banks make frequent changes to their statement layouts. They change fonts, add new logos, rearrange tables, or introduce new sections, sometimes without notice. These seemingly minor changes can break our carefully designed templates, making them unable to find the information they were built to extract, creating several challenges for us as developers:
- Continuous Maintenance: Templates need constant updates, which eats into engineering time.
- Time-Consuming: Each format change requires thorough testing and debugging.
- Scalability Issues: As we onboard more banks or as existing banks keep changing formats, maintaining and updating hundreds of templates becomes unsustainable.
Beyond the technical overhead, there’s a significant human cost: maintaining these brittle templates is repetitive and offers little in the way of exciting engineering challenges. Our developers are eager to tackle bigger, more impactful problems, not spend their valuable time debugging why a new font unexpectedly broke a transaction extraction
So, what’s an alternative solution?
The new frontier: Large Multimodal Language Models
What if we could skip templates entirely and instead teach our systems to understand what they’re looking at, not just where to look? Enter Large Multimodal Language Models (LLMs). These advanced AI models can process both images and text. They achieve this by integrating visual features (like the spatial arrangement of elements and visual cues) directly with the extracted text, allowing them to form a unified, contextual understanding of the document. This means they can “see” the layout of a document and “read” its content in context. For example, instead of rigidly instructing the system where to find the transaction table on Page 2, we let the LLM’s combined visual and linguistic understanding deduce that a grid of numerical values, especially those accompanied by date formats and common transaction descriptions, constitutes a transaction list.
This approach fundamentally changes the game for document extraction.
What does this new workflow look like?
Here’s how we’re evolving our pipeline using LLMs:
- Optimal Visual Input: We transform bank statement PDFs into high-resolution images. This gives our AI models the clearest possible visual information to work with.
- Intelligent Document Interpretation: These high-quality images are then fed into our sophisticated AI. This allows the system to simultaneously interpret both the visual layout and the textual content of the document.
- Contextual Data Recognition: Our AI performs highly advanced optical character recognition (OCR), but it goes much further. It truly understands what it’s seeing, distinguishing between different elements like headers and transactions, accurately recognizing account numbers, and identifying monetary amounts within their correct context.
- Actionable, Structured Output: The valuable data extracted by the AI is then seamlessly converted into a structured, easy-to-use digital format. This clean data is immediately ready for validation and integration into your existing systems for processes like reconciliation or customer onboarding, streamlining your operations
Why does this matter?
The advantages of LLM-powered extraction:
- Adaptability: LLMs can handle variations in document layouts without manual template updates.
- Scalability: We can easily add new banks without weeks of template engineering.
- Increased accuracy: Contextual understanding reduces errors, even with layout inconsistencies.
- Reduced development overhead: Engineers can spend less time on maintenance and more time building customer-facing features.
- Faster processing: New document formats can be processed almost immediately without waiting for template design and testing.
- Robustness: LLMs are less prone to failure when document formats change unexpectedly.
This is a massive shift in how we approach document processing, and it positions us to handle scale in a way that manual template maintenance never could.
But what about accuracy and certainty?
It’s a fair concern. While LLMs are powerful, they can occasionally hallucinate data (like confidently making up a total that doesn’t exist) if left unchecked. Since we’re often working with sensitive documents like payslips and bank statements, accuracy isn’t negotiable.
So, how do we ensure the data we extract is reliable?
We implement post-processing validation, including:
- Cross-validation: Checking whether transactions sum to the stated totals and ensuring that opening balances plus transactions equal closing balances.
- Cross-field validation: Confirming that transaction dates fall within the statement period and that account holder names are consistent throughout the document.
- Format consistency: Validating dates, account numbers, and currency formats to catch inconsistencies.
- Anomaly detection: Flagging unusual patterns like duplicate transactions, impossible dates, or outlier amounts.
- Business rule validation: Ensuring routing numbers and transaction codes align with known banking standards.
- Temporal validation: Checking that transactions follow logical chronological order.
- Confidence scoring: Flagging fields with low extraction confidence for human review.
- Completeness scoring: Measuring the percentage of expected data successfully extracted.
What will the future of document processing look like?
In 2025, having clean, structured data isn’t just a ‘nice-to-have’, it’s the difference between moving fast and getting stuck. If you’re working with documents in any serious way, being able to pull accurate data out of them quickly is a must.
Moving from brittle, template-based OCR pipelines to intelligent, adaptable LLM-powered workflows allows us to serve customers faster and with greater accuracy, while reducing manual maintenance that slows down teams. It’s how we’re preparing for scale, staying ahead of constant changes in the documents we process, and ensuring that the data we extract is not just data, but usable intelligence.
P.S. The marketing team made me include this, just kidding, our solutions are pretty epic, so it’s a no-brainer to chat to us about them 👇
If you’re interested in exploring how these advancements could optimise your document-heavy workflows, or if you’d like to discuss the unique challenges and opportunities of applying LLMs to real-world data extraction, we invite you to connect with us.
